
CNN articles highlight extraction
In this example, we will evaluate three models on how well they are able to extract highlights from news article.
Prepare the input dataset
We will use a dataset of CNN news article. You can download the JSONL file here.
Optional: make your own JSONL file
Download the test.csv file from this HuggingFace repository.
For long texts such as new articles, the CSV format can be inappropriate since the text will contain many characters that can be construed as value separators. JSONL would be much more appropriate.
To convert the CSV file to JSONL, use the following code snippet.
import csv
import json
with open("test.csv") as source:
reader = csv.reader(source)
with open("cnn.jsonl", "w") as destination:
for row in reader:
article = row[0].replace('\n', ' ')
payload = {"article": article}
destination.write(json.dumps(payload) + "\n")Upload the dataset
In the top menu bar, we click "New job".
Then select "JSONL file upload" in the Source type dropdown. Click "Choose file" and find your cnn.jsonl file.
Configure the models
In the central panel, click the + button to add a configuration for FLAN-T5.
Name your configuration, for example simply "FLAN-T5 XL". Select the XL variant, set the temperature to 0.1 and paste the following prompt.
Please extract the top three highlights from the following article.
Each highlight should contain no more than two sentences.
<article>{{article}}</article>
Then, configure as many other models and variants as you want. For example, Llama 2 7B and Falcon 7B.
Configure evaluation methods
AI scoring
We will configure three AI metrics to evaluate the quality of the output.
Activate the AI scoring section of the form.
Groundedness
We want to evaluate how grounded the extracted highlights are in the original article to gauge how much the models may be hallucinating.
Name the property "Groundedness" and add the following prompt.
The score describes how grounded the highlights are in the original article.
The following is the original article:
<article>{{article}}</article>
The following is a grading rubric to use:
1. The highlights are not grounded at all in the article. Most statements in the highlights are not grounded in facts present in the article.
2. The highlights are lightly grounded in the article. Some statements in the highlights are directly stated in the article.
3. The highlights are somewhat grounded in the article. Many statements in the highlights are grounded in the article.
4. The highlights are mostly grounded in the article. Some statements in the highlights are not grounded in the article.
5. The highlights are very grounded in the article. Most or all statements in the highlights are directly stated in the article.
Formatting
The prompt asked the models to extract exactly three highlights, so we want to evaluate whether this instruction was respected.
We create a "Formatting" property, and paste the following prompt.
The score describes how many highlights were generated.
The following is a grading rubric to use:
1. Less than three highlights were generated.
3. More than three highlights were generated.
5. Three highlights were generated.Highlight length
The prompt asked the models to use at most two sentences per highlight. We want to evaluate whether this instruction was respected. In total for three highlights, 3 to 6 sentences should be generated.
We create a "Highlight length" property and paste the following prompt.
The score describes how many sentences were generated.
The following is a grading rubric to use:
1. Less than three sentences were generated.
2. Three sentences were generated.
3. Four sentences were generated.
4. Five sentences were generated.
5. Six sentences were generated.Unsupervised metrics
Since this is a summarization task, the available unsupervised metrics are relevant so we activate them all.

Start the job
At the top of the form, name your job, for example "CNN articles highlights extraction 1". Then click the Start run button.
Airtrain will run inferences for 2,000 input examples and 3 models. Then, the scoring model will rate all 6,000 outputs across 3 metrics, that is 18,000 values to extract.
The job may take a couple of hours to complete. Go have lunch ;-)

Viewing results
Once the job has completed, head over to the Results tab to visualize results.
AI scores
In the top panel, we can visualize metrics distributions across the entire eval dataset.
Groundedness

We can see that Llama 2 7B in green has the highest average groundedness. The distribution is the most spiked around 5.
Formatting

We can see that Llama 2 was also the best at following instructions. Falcon and FLAN-T5 generated less or more than three highlights 20% and 35% of the time respectively.
Highlight length
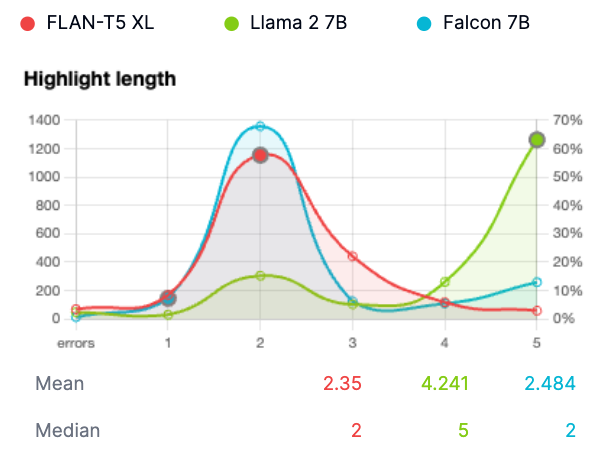
As expected, the majority of inferences scored 2 (3 sentences, i.e. one per highlight) or 5 (6 sentences, i.e. 2 per highlight). We can see that Llama 2 more frequently generated 2 sentences per highlights.
Updated about 2 months ago